Supervised Learning Techniques Training Course
Supervised Learning Techniques Training Course equips participants with the foundational knowledge and practical skills to build and deploy powerful predictive models.
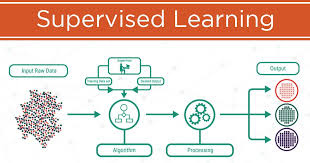
Course Overview
Supervised Learning Techniques Training Course
Introduction
In today's data-driven world, the ability to extract meaningful insights and make accurate predictions from data is paramount for organizational success. Supervised Learning Techniques Training Course equips participants with the foundational knowledge and practical skills to build and deploy powerful predictive models. By mastering key concepts such as regression analysis, classification algorithms, and model evaluation, learners will gain a significant competitive advantage in leveraging data for informed decision-making. This course delves into the intricacies of labeled datasets, exploring various algorithms from fundamental linear models to sophisticated neural networks and support vector machines. Through hands-on exercises and real-world case studies, participants will develop a deep understanding of how to apply these techniques to solve a wide range of business problems, ultimately driving innovation and efficiency within their organizations.
This intensive program is designed to provide a robust understanding of the supervised learning workflow, starting from data preparation and feature engineering to model selection, training, and performance optimization. Participants will learn to navigate the complexities of bias-variance trade-off, understand the importance of cross-validation, and gain proficiency in using industry-standard tools and libraries. By focusing on practical application and the latest advancements in the field, this course empowers individuals and teams to harness the full potential of predictive analytics and contribute directly to achieving strategic organizational goals.
Course Duration
5 days
Course Objectives
This training course aims to equip participants with the following key skills and knowledge:
- Understand the fundamental concepts and principles of supervised learning.
- Differentiate between various types of supervised learning algorithms, including regression and classification.
- Master techniques for data preprocessing and feature engineering to prepare data for modeling.
- Apply linear regression and understand its assumptions and limitations.
- Implement and evaluate various classification algorithms such as logistic regression, decision trees, and random forests.
- Grasp the principles and applications of support vector machines (SVMs).
- Explore the architecture and training of basic neural networks for supervised learning tasks.
- Learn effective methods for model selection and hyperparameter tuning.
- Apply appropriate metrics for model evaluation in both regression and classification.
- Understand and address the bias-variance trade-off in model building.
- Implement cross-validation techniques for robust model assessment.
- Gain practical experience using relevant machine learning libraries (e.g., scikit-learn).
- Apply supervised learning techniques to solve real-world business problems.
Organizational Benefits
- By leveraging predictive models, organizations can make more informed and data-driven decisions, leading to better outcomes.
- Automation of predictive tasks can streamline processes and improve operational efficiency across various departments.
- Organizations with strong data science capabilities can gain a significant edge by identifying market trends and customer behaviors more effectively.
- Equipped with supervised learning skills, employees can tackle complex business challenges and drive innovation through data-driven solutions.
- Accurate predictions can help organizations optimize resource allocation, reduce waste, and improve overall profitability.
- By understanding customer needs and predicting behavior, organizations can personalize experiences and enhance satisfaction.
- Supervised learning can be used to identify and predict potential risks, allowing organizations to take proactive measures.
- Investing in data science training fosters a data-driven culture within the organization, encouraging evidence-based decision-making at all levels.
Target Audience
This training course is ideal for professionals in various roles, including:
- Data Scientists
- Data Analysts
- Business Analysts
- IT Professionals
- Software Engineers
- Researchers
- Marketing Analysts
- Anyone interested in leveraging data for prediction and decision-making.
Course Outline
Module 1: Introduction to Supervised Learning
- Fundamentals of Machine Learning and Supervised Learning
- Types of Supervised Learning: Regression vs. Classification
- The Supervised Learning Workflow: Data Collection to Deployment
- Key Terminology: Features, Labels, Training Data, Test Data
- Applications of Supervised Learning in Various Industries
Module 2: Data Preprocessing and Feature Engineering
- Handling Missing Values and Outliers
- Data Scaling and Normalization Techniques
- Encoding Categorical Variables
- Feature Selection Methods
- Creating New Features from Existing Data
Module 3: Regression Techniques
- Simple Linear Regression: Concepts and Implementation
- Multiple Linear Regression: Dealing with Multiple Predictors
- Polynomial Regression and Non-Linear Relationships
- Evaluating Regression Models: Metrics like MSE, RMSE, R-squared
- Regularization Techniques: Ridge and Lasso Regression
Module 4: Classification Techniques I
- Logistic Regression: Binary and Multiclass Classification
- Decision Trees: Building and Interpreting Trees
- Random Forests: Ensemble Learning for Improved Accuracy
- Evaluating Classification Models: Accuracy, Precision, Recall, F1-Score
- Understanding Confusion Matrices and ROC Curves
Module 5: Classification Techniques II
- Support Vector Machines (SVM): Linear and Non-Linear Kernels
- K-Nearest Neighbors (KNN): Principles and Applications
- Naive Bayes Classifiers: Assumptions and Use Cases
- Ensemble Methods: Bagging, Boosting, and Stacking
- Dealing with Imbalanced Datasets
Module 6: Introduction to Neural Networks
- Basic Neural Network Architecture: Neurons, Layers, Weights, Biases
- Activation Functions: ReLU, Sigmoid, Tanh
- Forward Propagation and Backpropagation
- Training Neural Networks: Gradient Descent and Optimization
- Introduction to Deep Learning Concepts
Module 7: Model Selection and Evaluation
- Bias-Variance Trade-off: Understanding and Managing
- Cross-Validation Techniques: K-Fold, Stratified K-Fold
- Hyperparameter Tuning: Grid Search and Randomized Search
- Model Persistence and Deployment Strategies
- Ethical Considerations in Supervised Learning
Module 8: Advanced Supervised Learning Topics
- Time Series Forecasting using Supervised Learning
- Dimensionality Reduction Techniques: PCA and t-SNE
- Advanced Ensemble Methods: Gradient Boosting Machines (e.g., XGBoost, LightGBM)
- Introduction to Explainable AI (XAI) for Supervised Models
- Case Studies and Real-World Applications Deep Dive
Training Methodology
This course employs a blended learning approach that combines:
- Interactive Lectures: Engaging presentations covering theoretical concepts and practical applications.
- Hands-on Lab Sessions: Practical exercises using Python and relevant machine learning libraries.
- Real-World Case Studies: Analysis of real-world business problems solved using supervised learning.
- Group Discussions: Collaborative sessions for sharing insights and problem-solving.
- Individual Assignments: Practical tasks to reinforce learning and assess understanding.
Register as a group from 3 participants for a Discount
Send us an email: [email protected] or call +254724527104
Certification
Upon successful completion of this training, participants will be issued with a globally- recognized certificate.
Tailor-Made Course
We also offer tailor-made courses based on your needs.
Key Notes
a. The participant must be conversant with English.
b. Upon completion of training the participant will be issued with an Authorized Training Certificate
c. Course duration is flexible and the contents can be modified to fit any number of days.
d. The course fee includes facilitation training materials, 2 coffee breaks, buffet lunch and A Certificate upon successful completion of Training.
e. One-year post-training support Consultation and Coaching provided after the course.
f. Payment should be done at least a week before commence of the training, to DATASTAT CONSULTANCY LTD account, as indicated in the invoice so as to enable us prepare better for you.